Visualização de Dados com Matplotlib e Seaborn 📊
Uma das habilidades mais importantes num cientista ou analista de dados é a habilidade de criar visualizações representativas, bonitas, e que contem uma história clara sobre os dados as quais representam, independente de quem as veja.
Nesta seção, adentraremos no tópico de visualização de dados com Python usando os módulos Matplotlib e Seaborn.
Para os exemplos desse artigo, iremos utilizar dois datasets obtidos no Kaggle:
Airbnb Open Data - Tokyo, Japan (2023)
Huge Stock Market Dataset
Ambos os projetos estarão disponíveis no GitHub, e explicados em maiores detalhes na aba de projetos.
Visualizações Simples com pandas
Muitas vezes, numa análise exploratória, queremos verificar a distribuição de uma coluna rapidamente, ou observar um trecho de uma série temporal com facilidade. Para isso, podemos utilizar a funcionalidade integrada à pandas para plotagens.
Essa funcionalidade foi construída com a própria Matplotlib, e permite a criação rápida de gráficos simples.
| Positivos | Negativos |
|---|---|
| Plotagem facilitada | Baixa Customização |
Line Plot
Via de regra, podemos fazer:
df.plot(x='Column1', y='Column2', title='Title', kind='line')
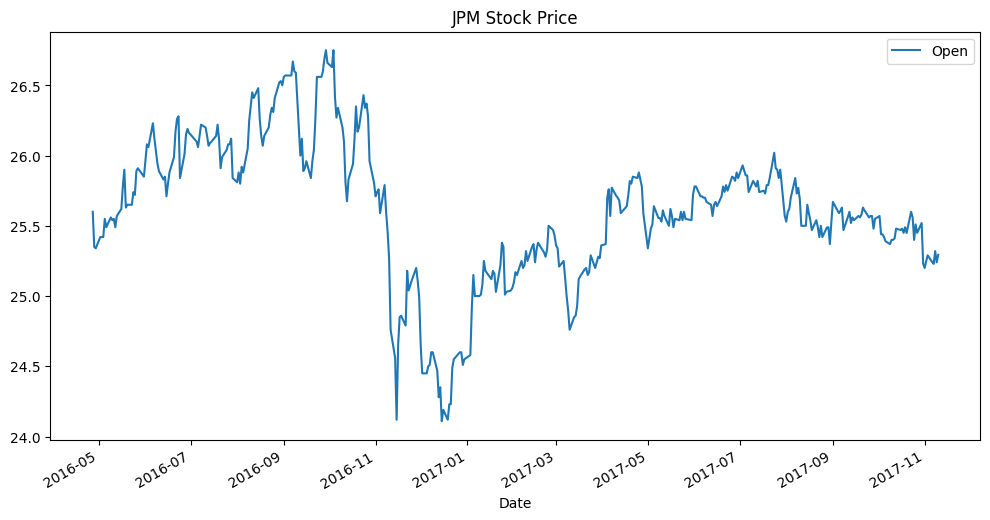
Vamos analisar como exemplo os valores de abertura, em dólares, da ação do banco internacional JP Morgan Chase, de 2016 até 2017.
#-Podemos plotar diretamente do DF, sem especificar o eixo X, que é o índice (index) por padrão
#-Caso queira/precise, basta especificar o eixo X com x = "..."
df_jpm.plot(y='Open', title='JPM Stock Price', kind='line', figsize=(12, 6))
Area Plot
Podemos utilizar essa plotagem para visualizar as Series do DF como áreas preenchidas:
df.plot(kind='area')
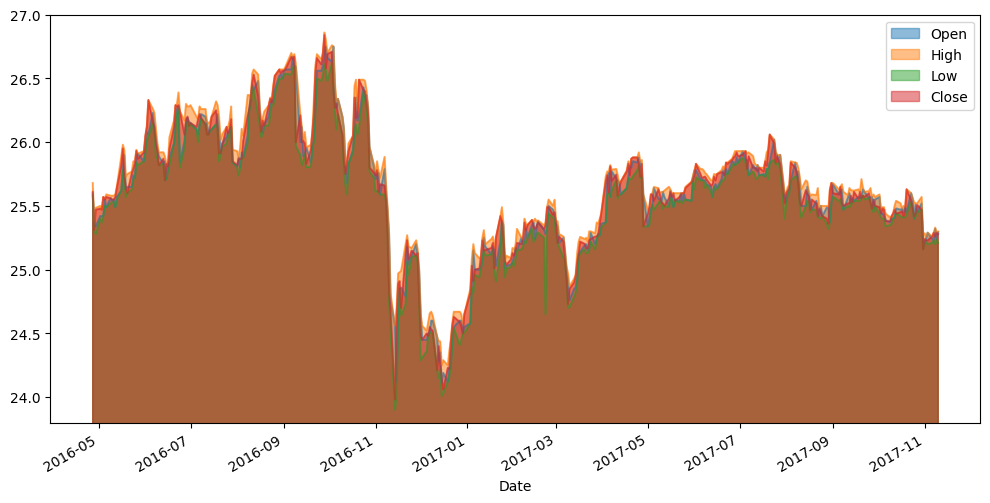
Replicando isso no nosso df_jpm, obtemos:
#-Selecionando somente algumas colunas do DF
values = df_jpm[['Open', 'High', 'Low', 'Close']]
#-Utilizando os parâmetros adicionais stacked e ylim
#-1. stacked:bool - se as Series devem se acumular uma em topo da outra
#-2. ylim:list/tuple - onde o eixo y deve iniciar e terminar
values.plot(kind='area', stacked=False, figsize=(12, 6), ylim=[23.8,27])
Histogram
Para visualizar a distribuição da frequência dos valores numéricos numa coluna, podemos utilizar o histograma:
df['column1'].plot(kind='hist', bins=20)
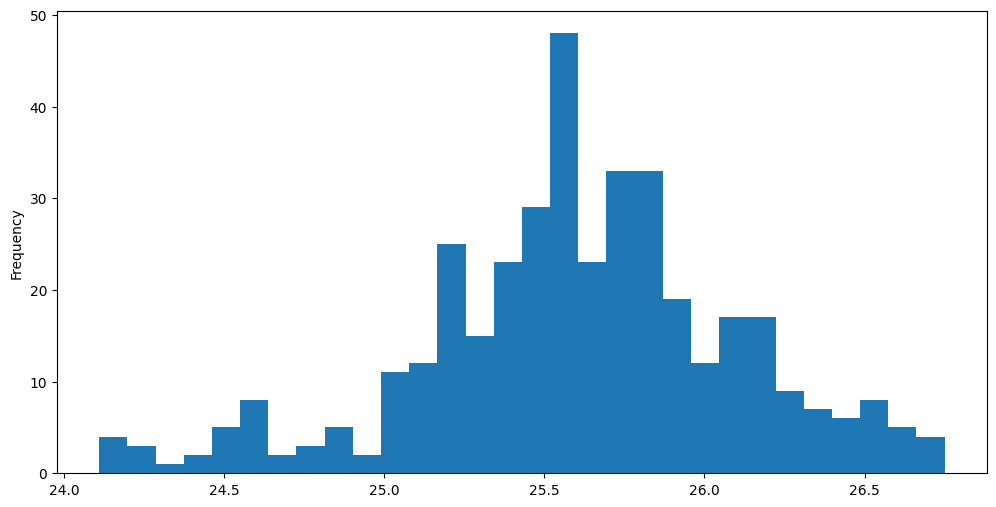
Vamos observar a distribuição da coluna de aberturas:
df_jpm['Open'].plot(kind='hist', bins=30, figsize=(12, 6))
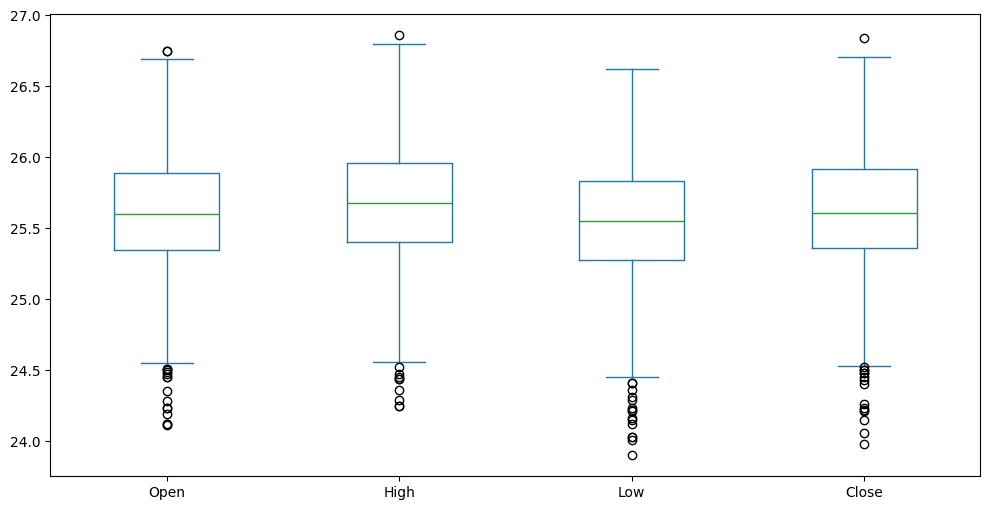
Box Plot
Podemos observar a distribuição de uma coluna, em conjunto com métricas estatísticas e outliers.
df.plot(kind='box')
Observe essa visualização aplicada no nosso sub-DF values:
values.plot(kind='box', figsize=(12, 6))
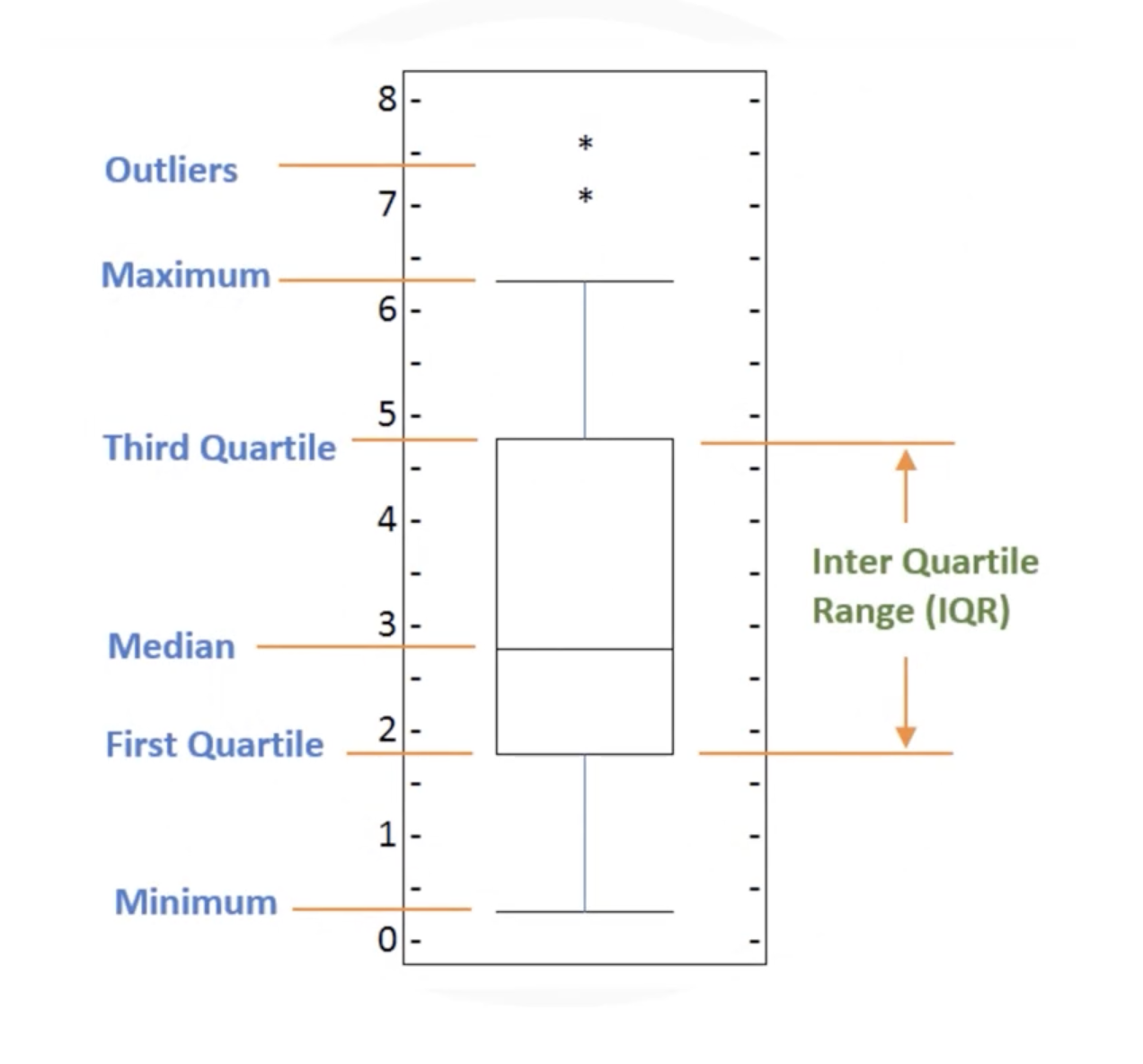
Outliers: pontos extremos
Máximo: valor máximo calculado sem outliers
Mínimo: valor mínimo calculado sem outliers
First Quartile (Primeiro Quartil): 25% dos registros são abaixo desse valor (localizado nos 1/4)
Median (Mediana): 50% dos registros são abaixo desse valor (valor intermediário)
Third Quartile (Terceiro Quartil): 75% dos registros são abaixo desse valor (localizado nos 3/4)
IQR (Inter Quartile Range): Intervalo entre o primeiro e o terceiro quartil (25%-75%)
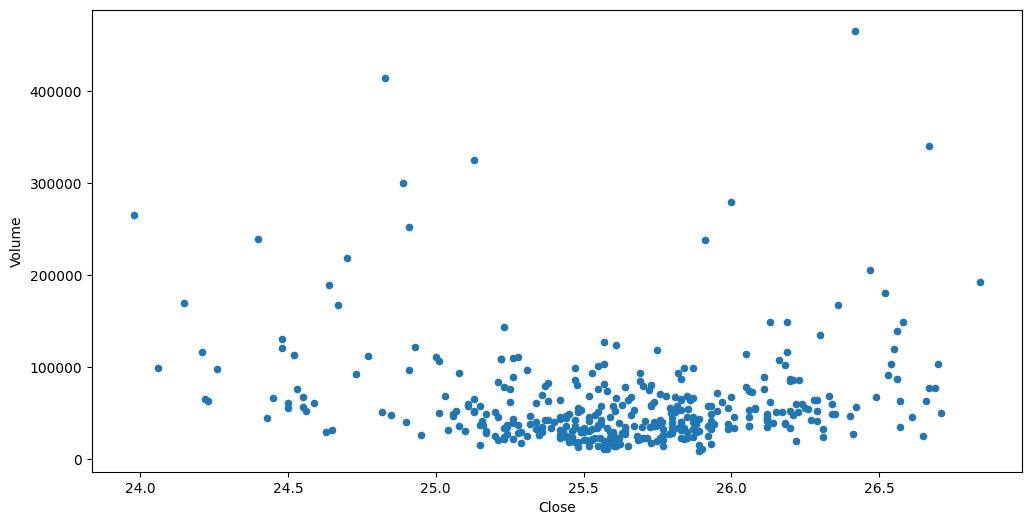
Scatter Plot
Essa visualização é composta de duas variáveis numéricas (de preferência, contínuas). É uma visualização exemplar em observação de correlações entre as variáveis.
df.plot(x="Column1", y="Column2", kind='scatter')
Vejamos a relação entre o volume de ações negociado e o valor de fechamento:
df_jpm.plot(x='Close', y='Volume', kind='scatter', figsize=(12, 6))
Pie Chart
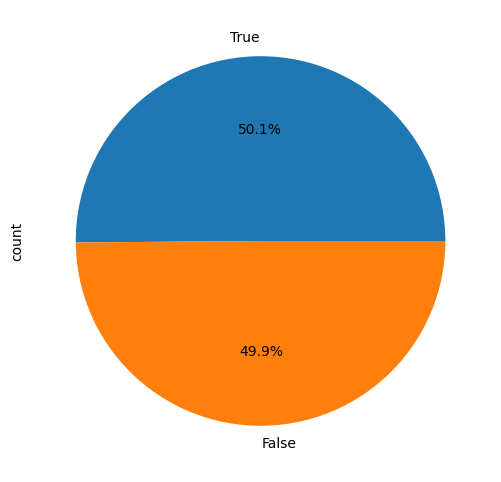
O clássico gráfico de pizza, representa a proporção de valores categóricos numa coluna.
df['column1'].plot(kind='pie', autopct='%1.1f%%')
Como no dataset de mercado financeiro não temos variáveis categóricas, podemos fazer:
#-Podemos criar uma nova coluna categórica que indica se o registro atual teve abertura maior
#-que o anterior, indicando crescimento.
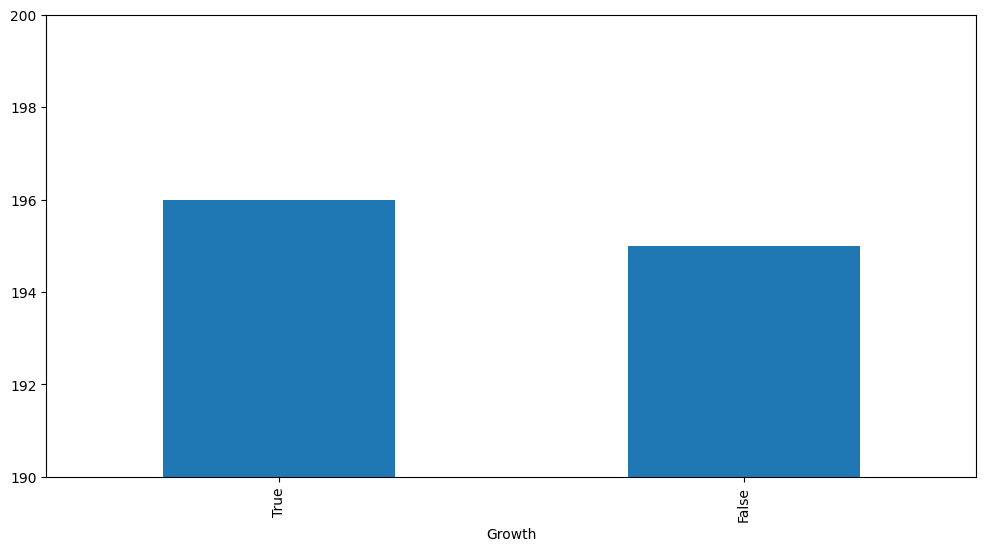
df_jpm['Growth'] = df_jpm['Open'] > df_jpm['Open'].shift(1)
df_jpm['Growth'].value_counts().plot(kind='pie', figsize=(6, 6), autopct='%1.1f%%')
Bar Chart
O gráfico de barras, amplamente utilizado para representar a contagem de uma coluna categórica ou uma relação entre uma variável categórica e uma numérica.
df.plot(kind='bar')
Como no dataset de mercado financeiro não temos variáveis categóricas, podemos fazer:
df_jpm['Growth'].value_counts().plot(kind='bar', figsize=(12, 6))
Visualizações completas com Matplotlib
A biblioteca mais famosa e utilizada para visualizações, Matplotlib, permite alto nível de customização e oferta muitos tipos de visualizações diferentes.
Esse módulo é composto de 3 camadas as quais podemos interagir em situações diferentes:
- Backend Layer (FigureCanvas, Renderer, Event)
- Artist Layer (Artist)
- Scripting Layer (pyplot, a mais utilizada no dia a dia)
Observe a anatomia de uma plotagem com Matplotlib:
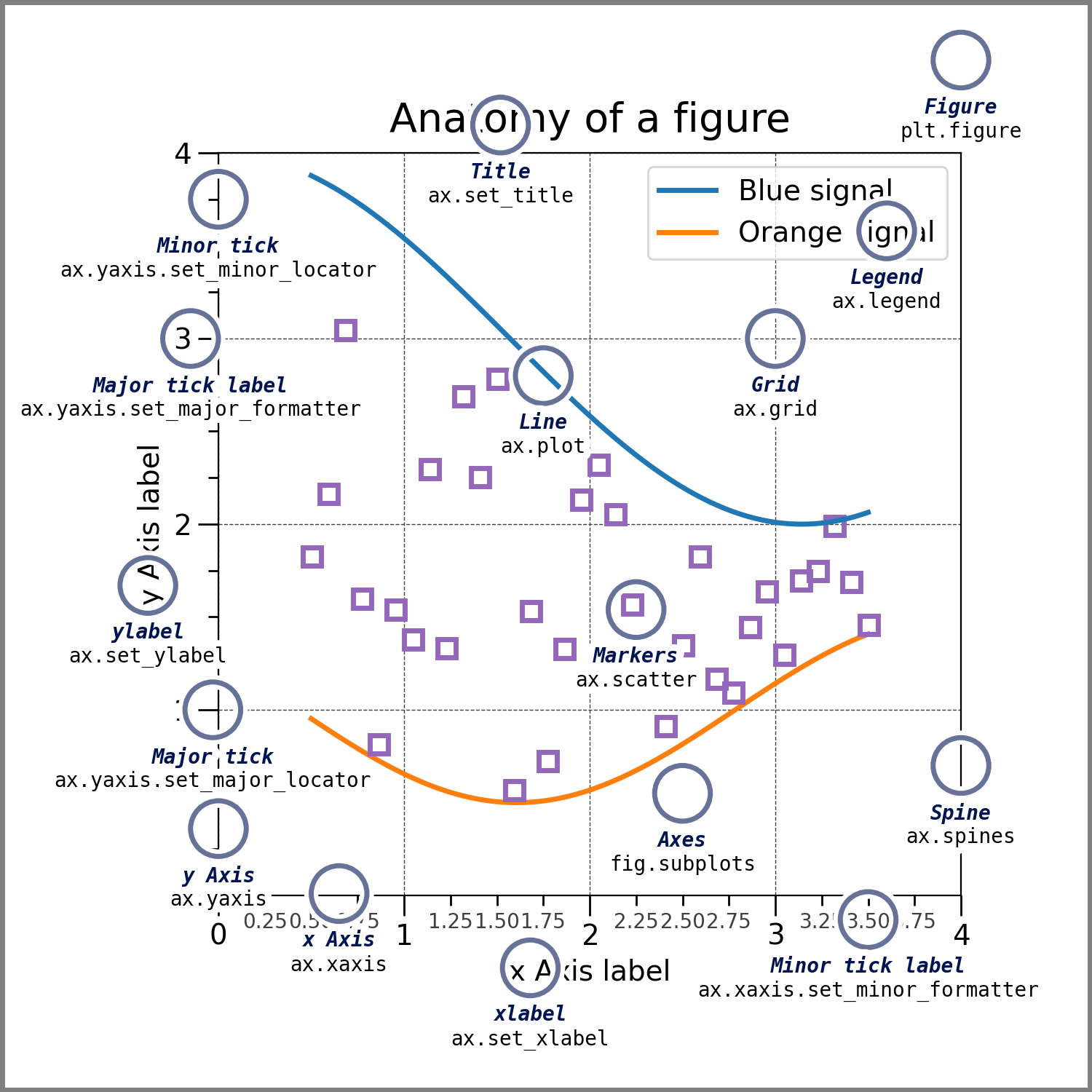
Observando acima, podemos perceber o nível de customização que essa biblioteca nos permite.
| Positivos | Negativos |
|---|---|
| Diversos tipos de plotagens disponíveis | Menor facilidade de manipulação |
| Alto poder de customização | Maior tempo e energia customizando |
Para as próximas visualizações, com exceção do Line Plot, usaremos outro conjunto de dados, especificado no início do artigo, de listagens de propriedades em Tokyo, Japão no Airbnb em 2023.
É possível selecionar um estilo para todos as suas visualizações. Para escolher o estilo, clique aqui e procure um que te agrada..
Depois, execute o comando:
#-Aqui, estamos utilizando 'ggplot', por exemplo
import matplotlib
mpl.style.use('ggplot')
Line Plot
Um gráfico de linha pode ser criado da seguinte maneira:
plt.plot(x, y, color='color', linewidth=1)
plt.title('Title')
plt.xlabel('X Label')
plt.ylabel('Y Label')
plt.show()
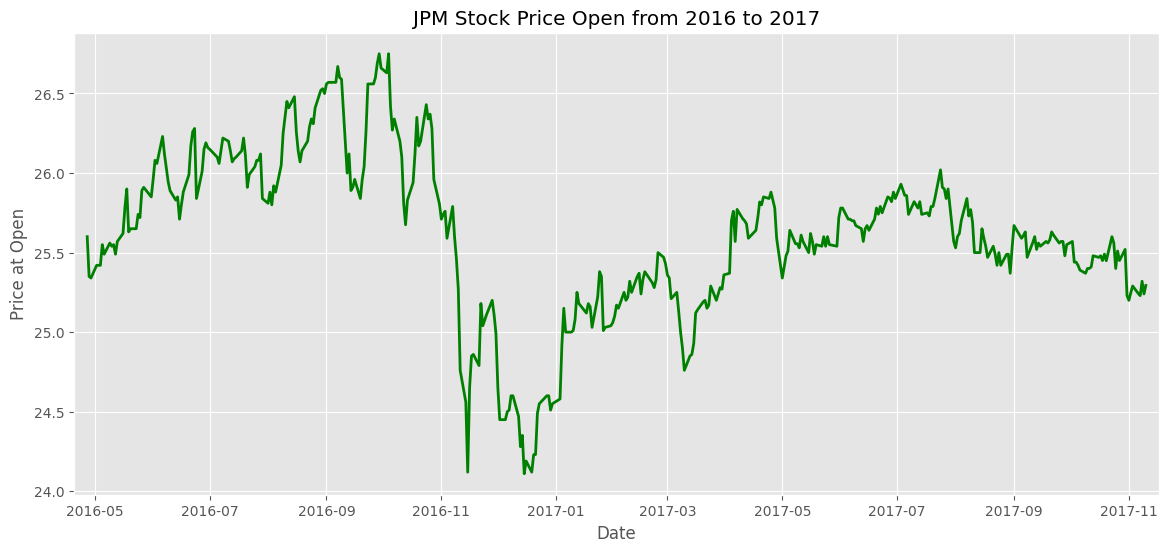
Para este exemplo, repetiremos o exemplo anterior de Line Chart do dataset da bolsa de valores americana.
#-Definindo o tam. da figura
plt.figure(figsize=(14, 6))
#-Plotando x,y
plt.plot(df_jpm.index,
df_jpm['Open'],
color='green',
linewidth=2,
linestyle='-')
#-Customizando o título e as legendas
plt.title('JPM Stock Price Open from 2016 to 2017')
plt.xlabel('Date')
plt.ylabel('Price at Open')
#-Colocando os limites do eixo X 1 semana antes e depois do primeiro e último registro
plt.xlim(df_jpm.index.min() - pd.Timedelta(days=7), df_jpm.index.max() + pd.Timedelta(days=7))
plt.show()
Com a Matplotlib, podemos até criar uma animação:
Código da Animação
import matplotlib.animation as animation
# Create a figure and axis
fig, ax = plt.subplots(figsize=(14, 6))
# Initialize an empty line object
line, = ax.plot([], [], lw=2)
# Set the x and y limits of the plot
ax.set_xlim(df_jpm.index.min(), df_jpm.index.max())
ax.set_ylim(df_jpm['Open'].min()-1, df_jpm['Open'].max()+1)
# Define the update function for the animation
def update(frame):
# Get the data for the current frame
data = df_jpm['Open'][:frame+1]
x = df_jpm.index[:frame+1]
# Update the line data
line.set_data(x, data)
return line,
# Create the animation
ani = animation.FuncAnimation(fig, update, frames=len(df_jpm), interval=20, blit=True)
ani.save('jpm_stock_price.gif', writer='pillow')
Area Plot
Um gráfico de área pode ser criado da seguinte maneira:
plt.fill_between(x, y1, y2, color=['color1','color2'], alpha=0.5)
plt.title('Title')
plt.xlabel('X Label')
plt.ylabel('Y Label')
plt.show()
Para este exemplo, repetiremos também o exemplo anterior de Area Chart do dataset da bolsa de valores americana.
#-Aqui, estamos plotando cada uma das colunas individualmente
plt.figure(figsize=(14, 6))
plt.fill_between(x=df_jpm.index,
y1=df_jpm['Open'],
color=['blue'],
alpha=0.3)
plt.fill_between(x=df_jpm.index,
y1=df_jpm['Close'],
color=['yellow'],
alpha=0.3)
plt.fill_between(x=df_jpm.index,
y1=df_jpm['High'],
color=['green'],
alpha=0.3)
plt.fill_between(x=df_jpm.index,
y1=df_jpm['Low'],
color=['red'],
alpha=0.3)
#-Customizando o título e as legendas
plt.title('JPM Stock Price Open, Close, High and Low from 2016 to 2017')
plt.xlabel('Date')
plt.ylabel('Price at Open')
#-Colocando os limites do eixo X 1 semana antes e depois do primeiro e último registro
plt.xlim(df_jpm.index.min() - pd.Timedelta(days=7), df_jpm.index.max() + pd.Timedelta(days=7))
#-Colocando os limites de y num quadro mais focado
plt.ylim(23.7, df_jpm['High'].max()*1.005)
plt.legend(['Open', 'Close', 'High', 'Low'])
plt.show()
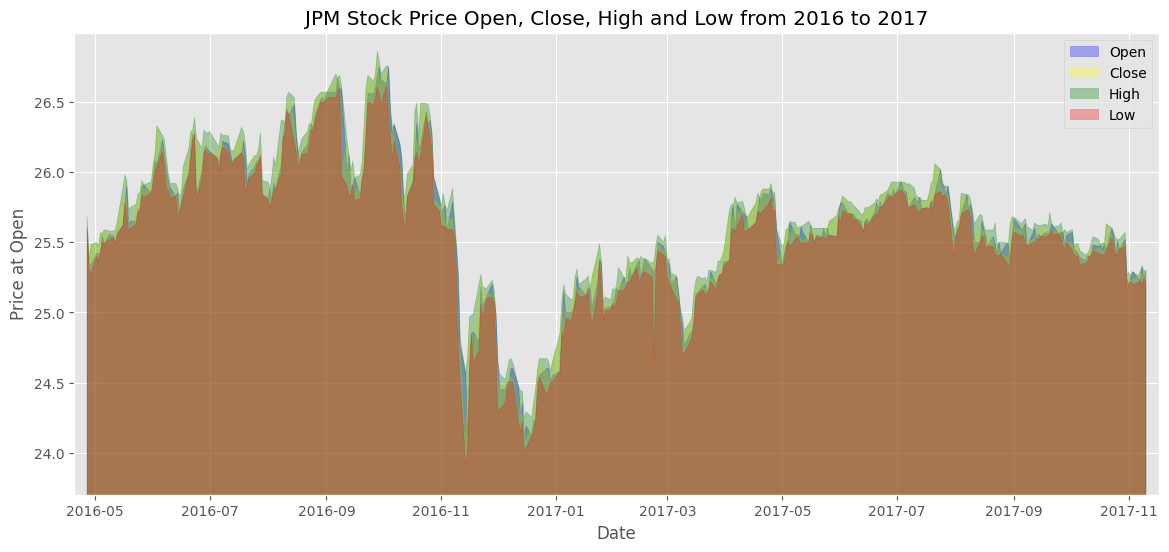
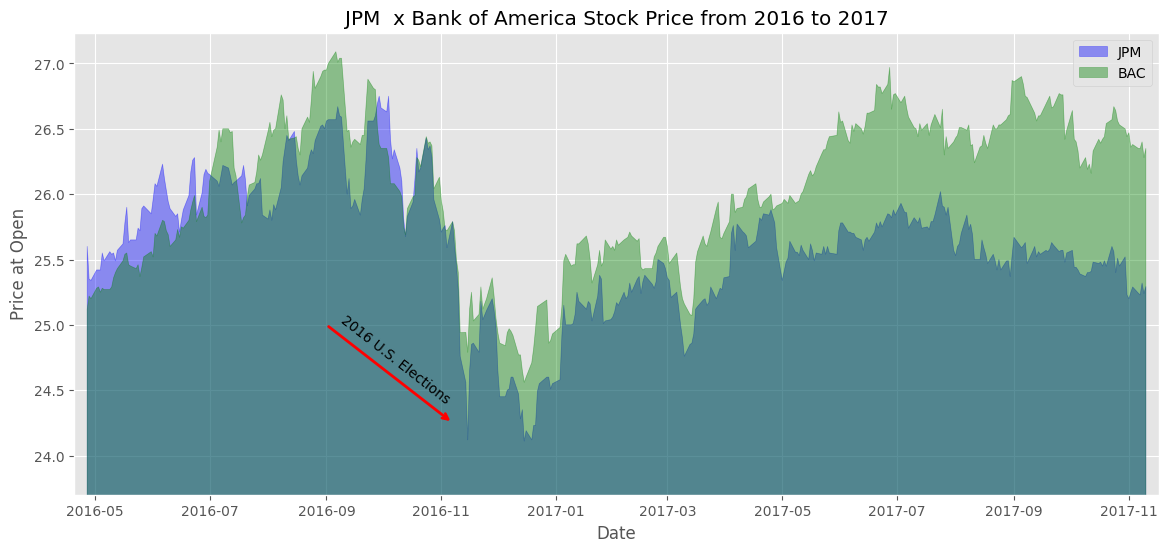
Não tem muita diferença do gráfico de área anterior... porém, agora podemos comparar diferentes DFs numa mesma visualização:
plt.figure(figsize=(14, 6))
#-Plotando os dados de JPM
plt.fill_between(x=df_jpm.index,
y1=df_jpm['Open'],
color=['blue'],
alpha=0.4)
#-Plotando os dados de BAC
plt.fill_between(x=df_bac.index,
y1=df_bac['Open'],
color=['green'],
alpha=0.4)
#-Customizando o título e as legendas
plt.title('JPM x Bank of America Stock Price from 2016 to 2017')
plt.xlabel('Date')
plt.ylabel('Price at Open')
#-Colocar os limites do eixo X 1 semana antes e depois do primeiro e último registro
plt.xlim(df_jpm.index.min() - pd.Timedelta(days=7), df_jpm.index.max() + pd.Timedelta(days=7))
#-Colocando os limites de y num quadro mais focado
plt.ylim(23.7, df_bac['High'].max()*1.005)
#-Legendando
plt.legend(['JPM', 'BAC'])
#-Adicionando uma linha para uma anotação
plt.annotate('',
xy=(df_jpm.index[135], 24.25),
xytext=(df_jpm.index[89], 25),
xycoords='data',
arrowprops=dict(color='red', arrowstyle='->', lw=2, connectionstyle='arc3'))
#-Adicionando o texto da anotação
plt.annotate('2016 U.S. Elections',
xy=(df_jpm.index[135], 24.4),
rotation=-38,
ha='right',)
plt.show()