SQL - Overview
Muitas organizações e empresas usam SQL (Structured Query Language) para acessar seu banco de dados. Um banco de dados é um conjunto de dados armazenado num computador, geralmente em tabelas, com múltiplas colunas e linhas.
Planilhas como Microsoft Excel e Google Sheets conseguem te permitir manipular e organizar dados diretamente, com seleção, filtração, ordenação, etc.
Aplicando essas operações, você pode separar o subconjunto de dados que procura. SQL (pronunciado "S-Q-L" ou "sequel") te permite escrever "consultas", ou queries, que definem o subconjunto dos dados que você procura.
A diferença? Diferentemente de Excel ou Sheets, seu computador e SQL vão decidir como conseguir os dados: você só precisa focar em definir quais dados você precisa. Você pode salvar essas queries, refiná-las, compartilhá-las e usá-las em outro conjunto de dados.
É uma ótima forma de acessar dados, e relativamente simples, com uma sintaxe não muito "enigmática".
Como isso pode ser usado?
Veja alguns exemplos de utilização abaixo:
- Funil de utilização
Um exemplo básico mas interessante é o de funil de utilização. Pense num e-commerce. O fluxo de uso se dá por 3 etapas:
- Navegação pela página e pelos itens à venda;
- Clique num ícone para iniciar o processo de compra e ir à página de checkout;
- Enviar informações de pagamento no checkout para completar a compra;
É natural que nem todos os visitantes do site vão chegar na etapa de checkout, e nem todos na etapa de checkout vão finalizar a compra. Isto é, a taxa de conversão nunca será 100%.
Esse tipo de processo é denominado funil. Sabendo disso, como podemos colocar nossas habilidades em SQL em prática para melhorar o site?
Podemos usar uma query para combinar dados dos usuários que visitaram diferentes seções da página, dados dos usuários que visitaram a página de checkout e dados dos usuários que finalizaram a compra.
Assim, podemos concluir a porcentagem estimada de usuários que movem para a próxima etapa no funil.
- Churn Rate (Taxa de Cancelamento)
Para plataformas e páginas com serviços por assinatura, podemos utilizar SQL para coletar dados de cancelamentos e calcular a taxa de cancelamento, que se dá por
Taxa de Cancelamento = (cancelamentos/total de inscrições)
E podemos fazer isso para analisar a churn rate todos os meses, para testar mudanças e melhorar o serviço.
Bom, vamos começar.
Manipulação das Tabelas
Já disse que os dados em bancos de dados relacionais são organizados em tabelas: mas como se parecem essas tabelas?
Veja um exemplo abaixo:
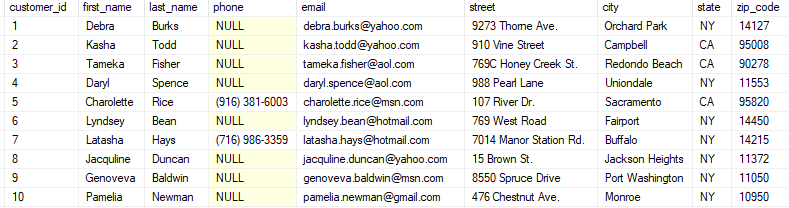
Podemos chamar as linhas de linhas, registros, ou rows, e as colunas de colunas, campos ou columns (que são os termos em inglês). Veja os comandos de manipulação que usaremos:
CREATE TABLE
A declaração CREATE TABLE cria uma nova tabela no banco de dados, com os nomes das colunas e os tipos de dados de cada coluna. Observe:
CREATE TABLE nome_da_tabela (
coluna1 TIPO_DE_DADO,
coluna2 TIPO_DE_DADO,
coluna3 TIPO_DE_DADO
);
Os tipos de dados vão depender do RDBMS usado: nós vamos usar os padrões do SQLite em alguns artigos e os padrões do PostgreSQL em outros. Neste artigo, estamos usando os tipos do SQLite, que são:
- INTEGER (Inteiro)
- TEXT (String)
- REAL (Float)
- DATE (Data no padrão YYYY-MM-DD)
Saiba também que chamaremos os comandos de cláusulas.
Aplicando num exemplo: imagine que queremos criar uma tabela que armazena dados sobre estudantes de uma escola. Veja:
CREATE TABLE estudantes (
matricula INTEGER,
nome TEXT,
idade INTEGER,
data_de_inicio DATE,
media REAL NOT NULL,
turma TEXT NOT NULL
);
Com esse comando nós criamos uma tabela simples que o nome dos estudantes, as idades, data de início na escola e a média geral das notas. Perceba que serão distintos uns dos outros com a categoria matricula.
As cláusulas e declarações ser escritas em letras maiúsculas, e são terminados em ponto e vírgula ;.
Restrições das Colunas (Column Constraints)
Em muitos casos, será interessante determinar algumas restrições para as colunas de nossas tabelas, para melhor organização, segurança e melhor adaptação e manipulabilidade.
Você pode ver as restrições como 'regras'. Veja quais são:
- PRIMARY KEY: pode ser usada para identificar cada instância da coluna, e não pode ter valor repetido, como uma 'chave';
- UNIQUE: colunas com essa restrição não podem ter valores repetidos;
- NOT NULL: colunas com essa restrição não podem ser nulas, isto é, vazias;
- DEFAULT: associa um valor default à coluna caso não tenha sido especificado;
A diferença entre essas restrições é que só se pode ter 1 coluna com a restrição PRIMARY KEY por tabela, enquanto podem existir diversas colunas com a restrição UNIQUE numa mesma tabela.
INSERT INTO
A declaração INSERT INTO é usada para adicionar novas LINHAS à uma tabela (é importante saber quais declarações servem para coluna e quais para linhas).
Pode-se ser escrita de duas formas:
- Inserir por NOME
- Inserir por ORDEM
Veja um exemplo:
-- Inserir em colunas por nome:
INSERT INTO nome_da_tabela
VALUES (valor1, valor2);
-- Inserir em colunas por ordem:
INSERT INTO nome_da_tabela (coluna1, coluna2)
VALUES (valor1, valor2);
Perceba que após a linha do INSERT INTO, não há ponto e vírgula. Não é um erro; é o padrão estético que devemos seguir quando escrevemos em SQL.
O comando poderia ser dado dessa forma:
INSERT INTO nome_da_tabela (coluna1, coluna2) VALUES (valor1, valor2);
Porém, para maior facilidade de leitura e interpretação, damos uma quebra de linha a cada cláusula. Nesse caso, as cláusulas são INSERT INTO e VALUES.
ALTER TABLE
A cláusula ALTER TABLE é usada para modificar as COLUNAS de uma tabela. Combinada com a cláusula ADD COLUMN, podemos adicionar colunas novas na tabela.
ALTER TABLE nome_da_tabela
ADD nome_da_coluna TIPO_DE_DADO;
Usando o exemplo passado, podemos modificar nosso código para algo como:
CREATE TABLE estudantes (
matricula INTEGER PRIMARY KEY,
nome TEXT UNIQUE,
idade INTEGER NOT NULL,
data_de_inicio DATE NOT NULL,
media REAL NOT NULL,
turma TEXT NOT NULL
);
-- Adicionamos uma coluna de Série (6°, 7°, 8°...)
ALTER TABLE estudantes
ADD serie INTEGER NOT NULL;
DELETE
A declaração DELETE combina a cláusula DELETE e WHERE, e deleta LINHAS de uma tabela. A cláusula WHERE identifica quais registros serão apagados. Se essa cláusula for omitida, todos os registros serão apagados.
DELETE FROM nome_da_tabela
WHERE coluna_x = valor_x;
Para apagar registros únicos e específicos, substitua o "valor_x" pela PRIMARY KEY do registro.
UPDATE
A declaração UPDATE é usada para editar registros, ou seja, LINHAS, numa tabela. Inclui uma cláusula SET que indica a coluna a ser editada e uma cláusula WHERE para especificar quais registros.
UPDATE nome_da_tabela
SET coluna_1 = valor_1, coluna_2 = valor_2
WHERE coluna_x = valor_x;
Queries
Também chamadas de consultas, as queries servem para buscar dados de um banco. Podemos fazer isso de muitas maneiras: puxar colunas específicas, puxar registros que atendem à uma condição específica, puxar dados ordenados, e etc.
Pense nas consultas como uma forma de se comunicar com a base de dados, e se expressando somente focando em quais dados você precisa, ao invés de como consegui-los.
SELECT
Para selecionar colunas num banco de dados, usamos a declaração SELECT, que combina as cláusulas SELECT e FROM, especificando quais colunas selecionar, de qual tabela, visto que um banco de dados relacional pode conter múltiplas tabelas (e geralmente contém).
Veja:
-- Nesta declaração, estamos selecionando todas as colunas da tabela1;
SELECT *
FROM tabela1;
Em SQL, nem sempre sabemos ou queremos escolher colunas ou registros absolutamente específicos. Por isso, a linguagem oferece alguns "curingas", que servem para selecionar tudo, ou selecionar tudo que se encaixe num padrão. Mais sobre isso adiante, mas por enquanto, o curinga "*" serve para selecionar todas as colunas com o SELECT.
Você também pode usar o SELECT com a cláusula AS, para dar um nome à coluna que desejar quando esta for mostrada na tela. Veja:
-- Neste exemplo, selecionamos a tabela de nomes de estudantes e vamos mostrá-la com esse título
SELECT names AS 'Nomes dos Estudantes'
FROM tabela_de_estudantes;
WHERE
Essa cláusula já vista antes pode ser combinada com a declaração SELECT FROM para dar condições de seleção, isto é, somente selecionar aqueles registros que obedecem à cláusula.
Veja:
-- Neste exemplo, selecionamos todos registros de uma tabela 'assinaturas'
-- onde a coluna 'year' é maior que 2020 (registros mais recentes);
SELECT *
FROM signatures
WHERE year > 2020;
Como muitas linguagens, SQL provê alguns operadores lógicos para efetuar comparações lógicas. Estes são:
- "=" para "igual à";
- "!=" para "não é igual à"
- "<" para "menor que"
- ">" para "maior que"
- "<=" para "menor ou igual à"
- ">=" para "maior ou igual à"
Note que, para comparação de valores nulos (quando não há valor, ou seja, valor vazio), não podemos usar os operadores acima. Devemos fazer:
- "IS NULL" para "é nulo"
- "IS NOT NULL" para "não é nulo"
Você pode comparar dois valores de colunas com a cláusula WHERE, como por exemlo:
-- Este exemplo seleciona somente os registros onde a latitude (lat) é maior que a longitude (lon)
SELECT lat, lon
FROM coordenadas
WHERE lat > lon;
DISTINCT
Essa cláusula é combinada com o SELECT para obter somente valores da coluna distintos, ou seja, únicos. É uma forma prática de saber quantos e quais categorias estão presentes nos registros.
Veja, por exemplo, numa tabela que contém nomes de filmes e seus gêneros (suponhamos comédia, romance, drama, terror e ação).
SELECT DISTINCT generos
FROM tabela_de_filmes;
Você veria 1 coluna com 4 registros: cada resgistro com um gênero. Mesmo se a tabela tivesse mais de 1000 filmes com cada gênero.
LIKE
SQL provê uma forma de encontrar dados e registros os quais você não conhece perfeitamente: só conhece uma parte. Ou, uma forma de encontrar dados que seguem algum padrão. A cláusula LIKE possibilita a pesquisa de registros os quais obedecem uma condição 'parcial':
-- Neste exemplo, usamos a mesma tabela fictícia do exemplo anterior. Imagine que todos os filmes de Hollywood estão na tabela.
SELECT nome
FROM tabela_de_filmes
WHERE nomes LIKE 'The %';
Você veria uma amostra somente com filmes cujos nomes começam com "The", como "The Avengers", "The Godfather", entre outros.
Retomando a ideia dos "curingas" em SQL, podemos utilizar o caractere "%" para que SQL complete um texto com os valores nos registros do banco de dados, como um 'placeholder'. Pode-se usar também o caractere "_" para completar somente um caractere ao invés do resto do texto.
ORDER BY
Usamos essa cláusula para ordenar as colunas mostradas, de alguma forma. Veja:
-- Neste exemplo, exibimos uma coluna de nomes dos estudantes, e ordenamos os nomes dos
-- alunos com a maior media até a menor media, ou seja, ordem decrescente de notas.
SELECT nome
FROM tabela_de_estudantes
ORDER BY media DESC;
Usando a cláusula ORDER BY, podemos utilizar duas palavras chave que determinam o método de ordenação:
- ASC: ascendente ou crescente
- DESC: descendente ou decrescente
Você também pode comparar textos, e estes serão comparados pela ordem lexicográfica, ou seja, a ordem do dicionário. A ordenação default da cláusula é ASC.
AND, OR
Para montar condições mais complexas, podemos usar os operadores AND e OR. O funcionamento é simples:
- OR é verdadeiro quando QUALQUER condição é verdadeira;
- AND é verdadeiro quando TODAS as condições são verdadeiras;
BETWEEN
Para selecionar registros numa faixa limitada, podemos usar BETWEEN. Veja:
-- Neste exemplo, selecionamos as matriculas, nomes e media dos estudantes com media entre 5 e 7
SELECT matricula, nome, media
FROM tabela_de_estudantes
WHERE media BETWEEN 5.0 AND 7.0;
Pode ser usado com textos também.
LIMIT
Os bancos de dados geralmente tem milhares, até milhões de registros. Portanto, nem sempre queremos todos eles. Para limitar o número de registros selecionados, usamos a cláusula LIMIT.
SELECT *
FROM tabela_de_estudantes
LIMIT 15;
Essa declaração vai selecionar até 15 registros de estudantes da tabela.
CASE
Pense nessa declaração como o método SQL da lógica if-then-else. Para selecionar e rotular registros com essa lógica, fazemos:
-- Esse exemplo irá condensar todos os alunos em aprovado ou reprovado de acordo com suas médias, e exibir em conjunto com os nomes.
SELECT nome, media
CASE
WHEN media >= 7.0 THEN 'APROVADO'
ELSE 'REPROVADO'
END AS 'Situação'
FROM tabela_de_alunos
Podemos usar a cláusula AS para dar um título à coluna.
Lembre-se sempre de terminar as declarações CASE com a cláusula END.
Funções Agregadas
Podemos usar queries, ou consultas, não só para acessar os dados, mas podemos também performar alguns cálculos neles, com funções do SQL. SQL possui algumas funções de fábrica. São úteis para diversas tarefas naturalmente monótonas, como contagem, busca de máximo e mínimo, etc.
COUNT()
Essa função retorna a quantidade de registros que obedecem à algum critério. Por exemplo:
--Este exemplo retorna a quantidade de alunos aprovados, ou seja, coma média maior ou igual à 7;
SELECT COUNT(*)
FROM tabela_de_estudantes
WHERE media >= 7.0;
Essa função também pode receber como argumento o nome de alguma coluna. Note que, passando como argumento o nome de uma coluna, COUNT() não irá contar valores nulos (NULL).
MAX()
Essa função toma uma coluna como argumento e retorna o maior valor na coluna. Veja:
--Este exemplo irá retornar a maior média da tabela e o nome
SELECT MAX(media), nome
FROM tabela_de_estudantes;
MIN()
Similarmente, essa função toma uma coluna como argumento e retorna o menor valor na coluna. Veja:
--Este exemplo irá retornar a menor média da tabela e o nome
SELECT MIN(media), nome
FROM tabela_de_estudantes;
SUM()
Essa função toma uma coluna como argumento e retorna a soma total dos valores numéricos dessa coluna. Veja:
--Este exemplo irá retornar a soma total das médias dos alunos;
SELECT SUM(media)
FROM tabela_de_estudantes;
AVG()
Essa função retorna a média simples de uma coluna, e toma uma coluna como argumento. Veja:
--Este exemplo retorna a média geral da turma 'A';
SELECT AVG(media)
FROM tabela_de_estudantes
WHERE turma = 'A';
ROUND()
Essa função toma 2 argumentos: um valor a ser arredondado e o n° de casas desejadas. O valor default é 0 (arredonda para o inteiro mais próximo). Veja:
--Neste exemplo, simplesmente arredondamos a média encontrada no exemplo passado com 1 casa de precisão;
SELECT ROUND(AVG(media))
FROM tabela_de_estudantes
WHERE turma = 'A';
GROUP BY
A cláusula GROUP BY é usada para agregar dados com certas características, tornando mais fácil a categorização e agrupação. Veja:
--Neste exemplo, agrupamos a média dos alunos por turma;
--Ordenamos da menor série até a maior;
SELECT serie, AVG(media)
FROM tabela_de_estudantes
GROUP BY serie
ORDER BY serie ASC;
As cláusulas ORDER BY e GROUP BY podem referenciar colunas selecionadas pelo SELECT, na ordem que aparecem na declaração. Por exemplo:
--Neste exemplo, agrupamos o n° de alunos por media, da menor para a maior
SELECT COUNT(*) AS 'Total de Alunos', media
FROM tabela_de_alunos
GROUP BY 2 -- 2 = media
ORDER BY 1; -- 1 = COUNT(*)
Nota: a cláusula GROUP BY vem depois de WHERE, mas antes de ORDER BY e LIMIT.
HAVING
Essa cláusula serve para filtrar ainda mais os resultados da consulta. É pareada com a cláusula GROUP BY. É bastante parecida com a cláusula WHERE, a única diferença é que normalmente é usada com funções agregadas para filtrar com base numa propriedade agregada.
Veja:
--Neste exemplo, selecionamos as series, a media por serie e a quantidade de alunos por serie,
--agrupando por serie, mas somente com series com mais de 15 alunos.
SELECT serie, COUNT(*), AVG(media)
FROM tabela_de_alunos
GROUP BY serie
HAVING COUNT(*) > 15;
Múltiplas Tabelas
Podemos trabalhar com múltiplas tabelas com SQL, extraindo informações significativas mais escondidas em dados de diferentes tabelas.
Inner JOIN
Uma das funcionalidades de SQL é a de combinar duas tabelas de uma base de dados. Como fazemos para combinar duas tabelas distintas?
Imagine que temos duas tabelas: a tabela orders, referente a pedidos de um produto, e a tabela customers, referente aos clientes que fizeram esses pedidos.
Como um mesmo cliente pode fazer vários pedidos distintos, faz mais sentido separar esses dados em duas tabelas diferentes, para deixar os dados mais limpos e menos repetitivos.
Vamos criar essas tabelas juntos:
CREATE TABLE orders (
order_id INTEGER PRIMARY KEY,
customer_id INTEGER NOT NULL,
order_qty INTEGER NOT NULL,
total_price REAL NOT NULL,
timestamp DATE
);
CREATE TABLE customers (
customer_id INTEGER PRIMARY KEY,
customer_name TEXT NOT NULL,
first_order DATE
)
Com essas tabelas criadas, podemos perceber que elas têm uma categoria em comum: customer_id. Podemos usar colunas em comum para fazer o Inner JOIN entre duas tabelas.
Veja:
--Neste exemplo, 'colamos' as tabelas no 'pedaço' em comum:
--a coluna 'customer_id'.
SELECT *
FROM orders
--Retornamos ambas as tabelas com esse código,
--juntando elas com a declaração JOIN,
--que combina as cláusulas JOIN e ON.
JOIN customers
ON orders.customer_id = customers.customer_id;
Aqui, podemos introduzir um conceito importante.
Perceba que, no exemplo acima, a coluna 'customer_id' é a chave primária (PRIMARY KEY) da tabela 'customers', e está presente na tabela 'orders', sem ser uma chave primária.
Caso não lembre o que é uma chave primária:
- Usada para identificar cada registro único;
- Não pode ter valor NULL;
- Só uma coluna PRIMARY KEY por tabela;
Quando uma chave primária de uma tabela aparece em outra, a chamamos de chave estrangeira (FOREIGN KEY).
Por que isso é importante?
Isso é importante por que o tipo mais comum de JOIN é juntar uma chave estrangeira com uma chave primária. É o que faremos na maioria das vezes.
Por exemplo, quando juntamos orders.customer_id (estrangeira) com customers.customer_id (primária).
Veja este exemplo gráfico (ignore as colunas f_name e l_name):
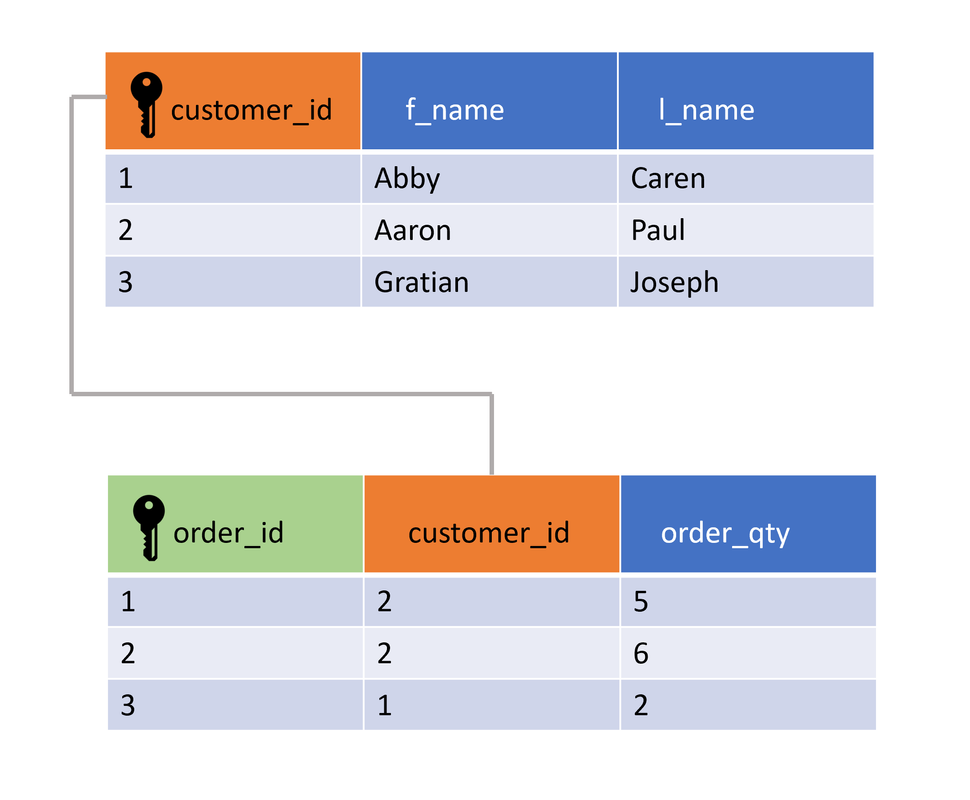
O 'JOIN' default é o INNER JOIN, que só retorna registros os quais a coluna usada para o JOIN é igual nas duas tabelas.
Isso significa que, se a condição "orders.customer_id = customers.customer_id" não for verdadeira, o registro não será retornado.
Outer JOIN
Uma cláusula Outer JOIN irá combinar os registros de diferentes tabelas, mesmo se a condição do JOIN não for satisfeita.
Num LEFT JOIN, todos os registros na tabela 'esquerda' é retornada, e se a condição do JOIN não for satisfeita, todos os valores da coluna 'direita' serão preenchidos com NULL. Veja:
SELECT *
FROM orders
LEFT JOIN customers
ON orders.customer_id = customers.customer_id;
CROSS JOIN
A cláusula CROSS JOIN é usada pra combinar cada registro de uma tabela com cada registro de outra. Isso é particularmente útil para criar todas as combinações possíveis para os registros em duas tabelas.
Veja:
--Aqui combinamos todos os ID's de ambas as tabelas
SELECT orders.orders_id, customers.customers_id
FROM orders
CROSS JOIN customers;
UNION
A cláusula UNION permite a combinação de diferentes declarações SELECT, e filtra os resultados repetidos, desde que:
- As tabelas tenham o mesmo n° de colunas;
- Essas sejam do mesmo tipo de dado;
Veja:
SELECT orders.timestamp
FROM orders
UNION
SELECT customers.first_order
FROM customers;
WITH
A cláusula WITH armazena o resultado de uma querie anterior numa tabela temporária, para que seja possível realizar operações e consultas adicionais nessa tabela.
Múltiplas tabelas temporárias podem ser definidas com uma ocorrência de WITH.
--Neste exemplo, só referenciamos a tabela 'orders' de outra forma, e
--selecionamos os registros com mais de 3 pedidos;
WITH tabela_temporaria AS (
SELECT *
FROM orders
)
SELECT *
FROM tabela_temporaria
WHERE order_qty > 3;
Conclusão 🎑
Bom, essa seção termina aqui. Caso tenha alguma dúvida que não conseguiu encontrar online, envie para raphaelsoaresbrasil@gmail.com. Obrigado pela atenção, e bons estudos.